- Excelling With DynamoDB
- Posts
- The Single Table Design Vs Multi-Table Design In DynamoDB
The Single Table Design Vs Multi-Table Design In DynamoDB
The how and why of using both table design patterns in DynamoDB
Uriel Bitton
June 28, 2025

The single table design is a design pattern used that enables more efficient relational data storage in DynamoDB.
The motivation behind the single table design is this:
“Data that is fetched together, should be stored together”.
A good example is an e-commerce application database. Records like users, orders, transactions are always fecthed together. Managing these records across different database tables is inefficient because NoSQL database have no join capabilities.
To remedy this, we store these related entities together, resulting in faster queries.
The following diagram illustrates the efficiency optimization of the single table design.
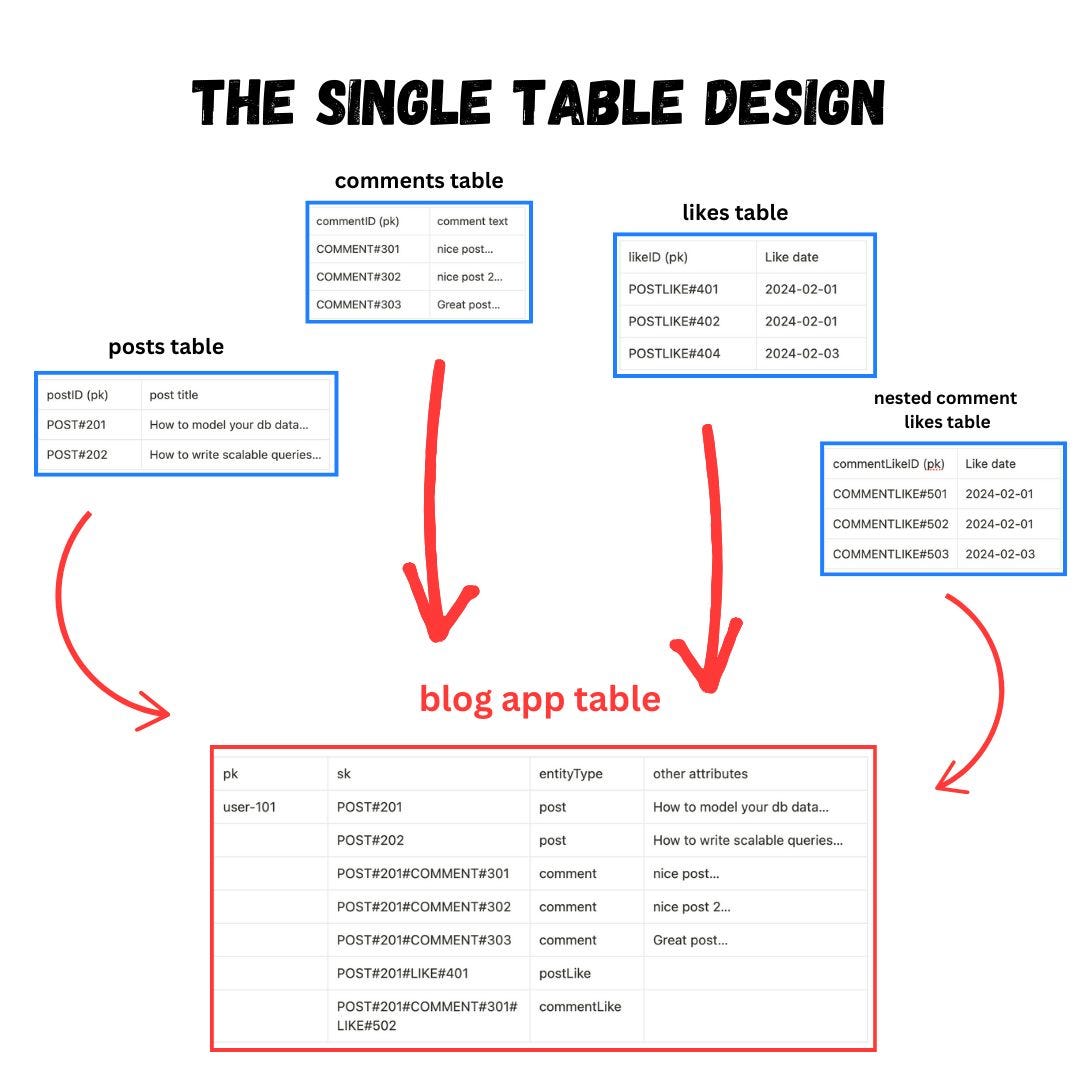
With this design, we do not have to run sequential queries across the four different tables. Instead, we can query a single partition (user-101) for their related data like posts, comments and like items.
How to design for a single table database
Contrary to implementing a multi-table design, the single table design requires you to think deely about the relationship between the data stored on your tables.
With a multi-table design, you need not concern yourself with the partition and sort key as much.
The partition key can be something like “product#101”, “order#101” or “user#101”. The sort key can be a simple date to sort the items.
With a single table design, this primary key design doesn’t work well.
Since we are storing all our data on one table, we must first group them in heirarchical fashion and use a more complex composite primary key design.
Here are a few examples of our primary keys for our data on the single table:
User Item
We can fetch a simple user’s data by using their (pk) userID (and using the static string “info”).
pk: "user#101",
sk: "info"Order Item
Since our data is now stored relationally, we need to store a user’s order items inside their user partition. We can achieve this like so:
pk: "user#101",
sk: "order#201"We can now understand the motivation for, and the advantage, of using a single table over a multi-table design: fetching all orders for a given user is now a simple and single query operation.
The same design principle applies to other related items, like transactions, shipments, etc.
Transaction Item
pk: "user#101",
sk: "transaction#301"How to design for a multi-table database
The multi-table design is trivial and typical of most other NoSQL databases.
We can create one table for each entity:
Users table
Orders table
Transactions table
Shipments table
Then for each of these items in each table, our primary key is also trivially structured:
Users
------
userID: "101",
email: "[email protected]"
Orders
------
orderID: "201",
orderDate: "2025-01-01T12:00",
userID: "101",
Transactions
------
transactionID: "301",
transactionDate: "2025-01-01T12:00",
orderID: "201",This classic design allows for simplicity and separation of concerns. It also allows you to store related entities within each other for referencing.
When to use which design pattern
An essential question which you must understand is when to use the single table design over the multi-table design and vice versa.
The most accurate answer is that you’ll know from experience after working with many different projects.
But here’s a general guideline.
Use the single table design when you:
Have multiple entity types that share access patterns or relationships.
Need to optimize for latency and costs. One table minimizes the number of queries and reduces provisioning throughput in DynamoDB. (also the more tables you have the more global secondary indexes you will pay for).
Are building a high performance application with well-defined and predictable access patterns.
Prefer fewer network round trips and are experience with designing partition and sort keys (key overloading, heirarchical designs and filtering, etc).
Use a multi-table design when you:
Have completely isolated entities with independent scaling or lifecycle needs.
Need simpler schema management (like with smaller projects).
Are dealing with evolving access patterns where a single table would become too complex (you must weigh the tradeoffs on costs and performance here).
Want clearer separation of concerns between domains and microservices.
The bottom line, again is that no matter your choice on single or multi table design, you must always evaluate the tradeoffs between the two choices.
The single table design offers cost and performance benefits, while sacrificing readability and making maintainability a little complex.
The multi table design offers simplicity, maintainability but sacrifices costs and performance.
Always evaluate these tradeoffs when architecting your database solution with DynamoDB.
👋 My name is Uriel Bitton and I hope you learned something in this edition of Excelling With DynamoDB.
📅 If you're looking for help with DynamoDB, let's have a quick chat.
🙌 I hope to see you in next week's edition!