- Excelling With DynamoDB
- Posts
- The Reason You're Using Scan In Your DynamoDB Queries
The Reason You're Using Scan In Your DynamoDB Queries
And how to replace them with efficient queries.
Uriel Bitton
April 05, 2025
Perhaps the #1 most common (and deadly) mistake I’ve seen users make in DynamoDB is using the Scan method inappropriately.
It’s almost always about bad data modeling.
Here’s why…
The Problem
You have some “users” data on your table.
You want to be able to fetch users by country, state (province) and/or city.
But user items are stored and uniquely identified by their userID values.
E.g. userID: “12345–67890”.
This only lets you get one user. You provide a userID and that only matches one single user.
But fetching multiple users — e.g. all users in a given city — requires a more complex data model.
So you use Scan and add a filter expression that says “contains(“city”, “Montreal”).
This will successfully get you all users in Montreal.
The only problem is this method is extremely inefficient. Your Scan operation will go through each item in your table and return only the matched items.
If you have 100,000 users, this operation will be extremely slow and costly.
The Naive Solution
The simple (and naive) solution to this issue is to create a GSI — a global secondary index.
This index can use “city” as a partition key and “userID” as the sort key.
Now you can provide a city name and query all users in that city.
However this approach adds overhead:
you need to pay extra for this GSI
you now have two places you can query data (confusing)
If you want to also fetch users by country and province (state), you need more GSIs (not efficient)
Is there a more efficient solution that requires no GSIs at all and keeps costs the same?
The Efficient Solution
A better solution is to shard our partition key, overload it and modify the data model to enable the access patterns of querying users by location, whether it’s by country, province or city.
Consider this data model (I’ll use “pk” and “sk” as partition and sort key names).
pk: users#<country>
sk: <province>#<province name>#<city>#<city name>Now instead of creating 3 GSIs and querying them for users in a given country, province or city, we can use a single base table with the following data model example:
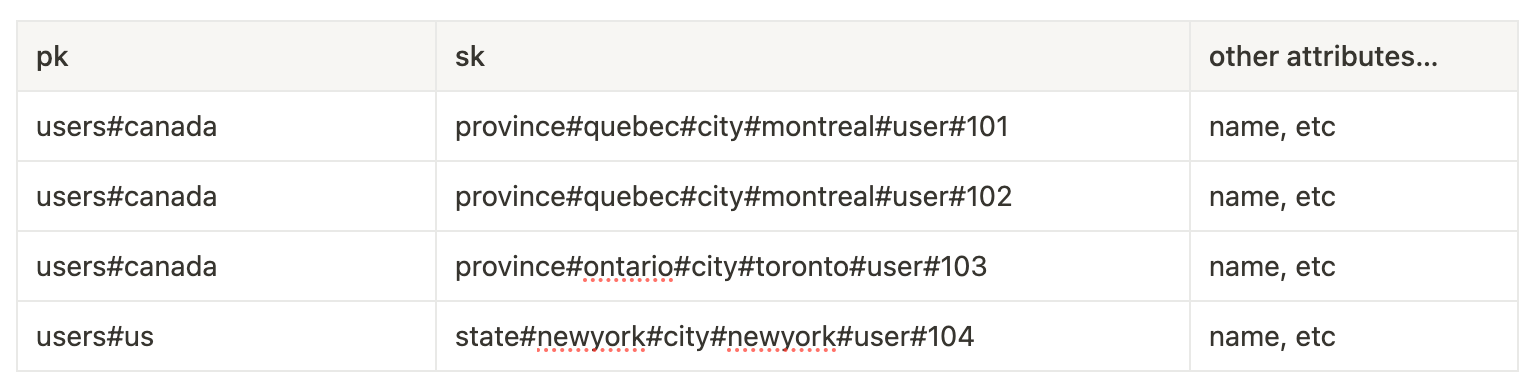
Now we can run the following queries on this base table:
1. Get all users in Canada
If we want to get a list of all users in Canada for example, we can run the following query:
TableName: "users",
KeyConditionExpression: "pk = :pk AND begins_with(sk, :sk)",
ExpressionAttributeValues: {
":pk": "users#canada",
":sk": "province#",
},This query would find the partition “users#canada”, and retrieve all items whose sort key (sk) begins with the string “province#”.
In other words: all user items.
2. Get all users in Quebec
If we want to get all users in Quebec, inside Canada, for example, we can run the following query:
TableName: "users",
KeyConditionExpression: "pk = :pk AND begins_with(sk, :sk)",
ExpressionAttributeValues: {
":pk": "users#canada",
":sk": "province#quebec#",
},This time just by adding to the sk string “quebec#” we include all users in the province of quebec.
3. Get all users in Montreal
If we want to get all users in Montreal, for example, we can run the following query:
TableName: "users",
KeyConditionExpression: "pk = :pk AND begins_with(sk, :sk)",
ExpressionAttributeValues: {
":pk": "users#canada",
":sk": "province#quebec#city#montreal",
},Again we add on to the sk string “montreal#” and that gives us all users in the city of Montreal.
Finally, if we wish to get just one user (by their userID) we have a choice:
we can get it by knowing their location (country/province/city), or,
we can create a GSI and add userID as the partition key and use that to query single user items.
Choosing between the two cases always depends on your application’s access patterns.
Conclusion
The bottom line is this: avoid Scans as much as possible.
In fact, you should probably never use them if you are not running either analytical queries (for a dashboard, BI, etc) or a data migration where you need to move/copy your database tables elsewhere.
99% of your Scan() issues come from the fact your database table isn’t well designed.
A solid data model will solve all of your inefficiencies and allow you to never reuse Scan methods on your tables again, saving you time and money in the process.
👋 My name is Uriel Bitton and I hope you learned something in this edition of Excelling With DynamoDB.
📅 If you're looking for help with DynamoDB, let's have a quick chat.
🙌 I hope to see you in next week's edition!