- Excelling With DynamoDB
- Posts
- Designing A Social Media Database With DynamoDB
Designing A Social Media Database With DynamoDB
Using the single table design to efficiently query and store related data
Uriel Bitton
March 29, 2025
ave you ever wondered how social media giants, like Facebook and Linkedin, store and query the data on their databases?
To be able to support millions of reads and writes per second?
To facilitate sending hundreds of millions of messages per minute between users.
Most of their solutions involve complex system designs and architecture.
At the database level, the data probably has to be well-sharded and designed with the intention for scalability.
But each platform has their solution, data design and data model and its rarely something that is publicized.
In this article, I’ll offer my take on how you can create a highly scalable social media database design that could equally handle millions of requests per second.
As always my solution will involve DynamoDB and the single table design pattern.
Identifying Data Access Patterns
Photo by Alexander Shatov on Unsplash
To design our database for a scalable social media use case, we’ll first identify the primary access patterns that our app will require.
I’ve identified the following 7 important access patterns:
Get the feed of posts for a given user, sorted chronologically
Get a user’s profile by their user ID
Get posts created by a given user
Get a post by its post ID
Get all comments on a given post
Get all likes on a given post
Get a user’s followers
Next, we’ll call the table “social-media” and store the following entities:
Users
Posts
Comments
Likes
Single Table Data Model
Photo by Alexander Shatov on Unsplash
Let’s see now how we can model the data for this single table.
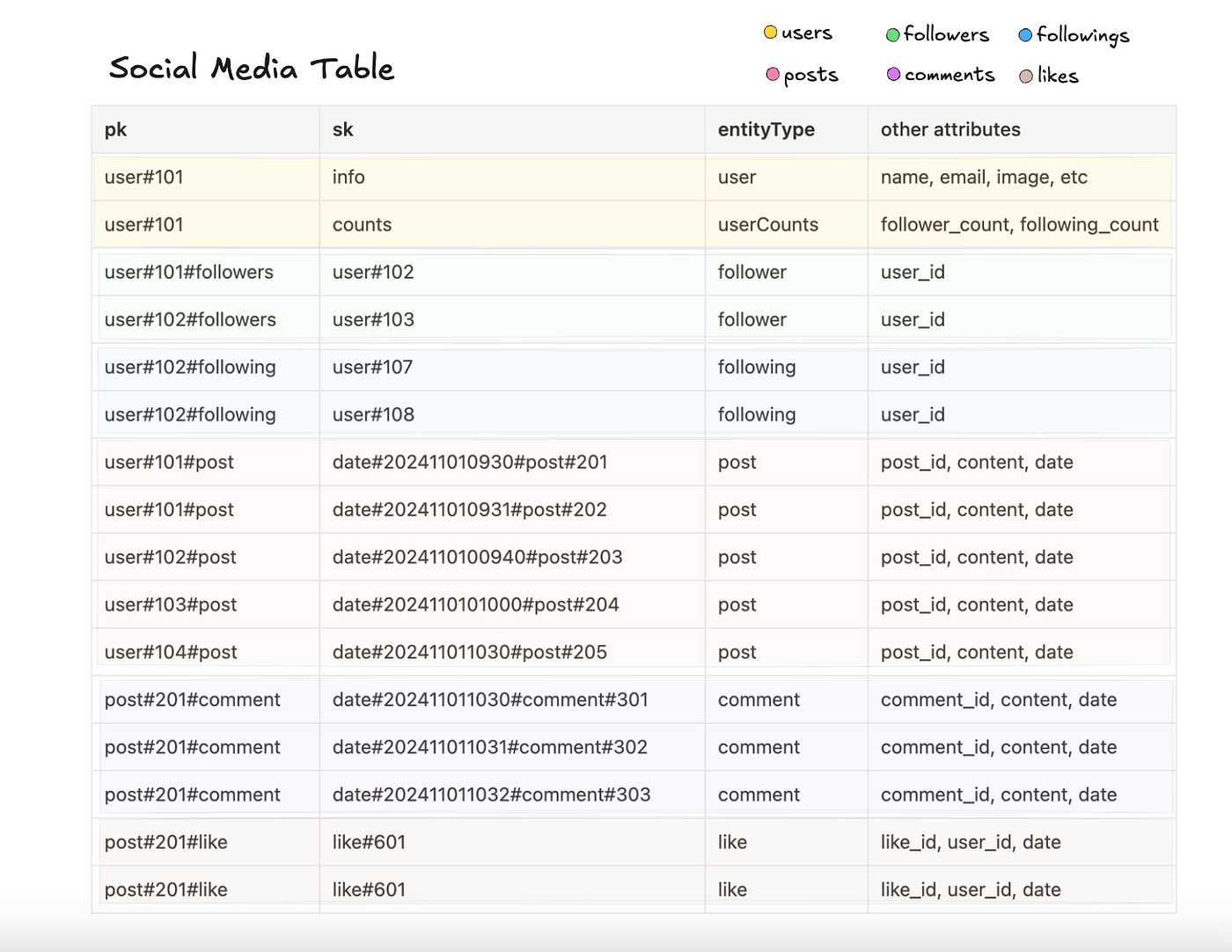
Let’s briefly explain the table design we chose above.
Our primary access pattern is retrieving posts to display on a user’s feed.
To satisfy this access patterns I have designed the partition and sort keys of post items (light red highlight) like this:
pk: user#101#post
sk: date#202411010930#post#201The partition key defines the user who wrote the post (using their user ID) and is suffixed with “#post”.
The sort key is prefixed with “date#”, appends the date-time as a string, and is suffixed with the post ID (i.e post#201).
Fetching Posts
To fetch posts to populate a given user’s feed we will get a batch of 20 or so users which this user is following, and query these partitions.
The results are of course sorted according to date in the sort key so that we can fetch the most recent posts first.
Writing Post Items
To write posts to our database we use post user’s user ID as the partition key. For the sort key, we use the date and time it is published as well as a random ID for the post.
When a given user follows another user, we create a “following” item (highlighted in light blue above) with that user’s user ID as the sort key.
Then, when we need to display to a user the posts from users they follow, we query 20 “following” user items, and for each of these users, we query the “posts” partition in batches of 20.
This is how we populate any given user’s feed.
You should of course consider client-side caching here so you don’t run this query too often.
1. Get the feed of posts for a given user
This also satisfies our first access pattern, “Get the feed of posts for a given user, sorted chronologically”.
We query the table, specify the pk and sk keys and we use the ScanIndexForward attribute set to false to display the results from most recent to oldest.
We can run these queries in parallel.
//multiple parallel queries
TableName: SocialMedia,
KeyConditionExpression: pk = "user#101#post" AND begins_with(sk, "date#")
ScanIndexForward: false
TableName: SocialMedia,
KeyConditionExpression: pk = "user#102#post" AND begins_with(sk, "date#")
ScanIndexForward: false
...more queriesThese queries would return all of the items, as seen below.
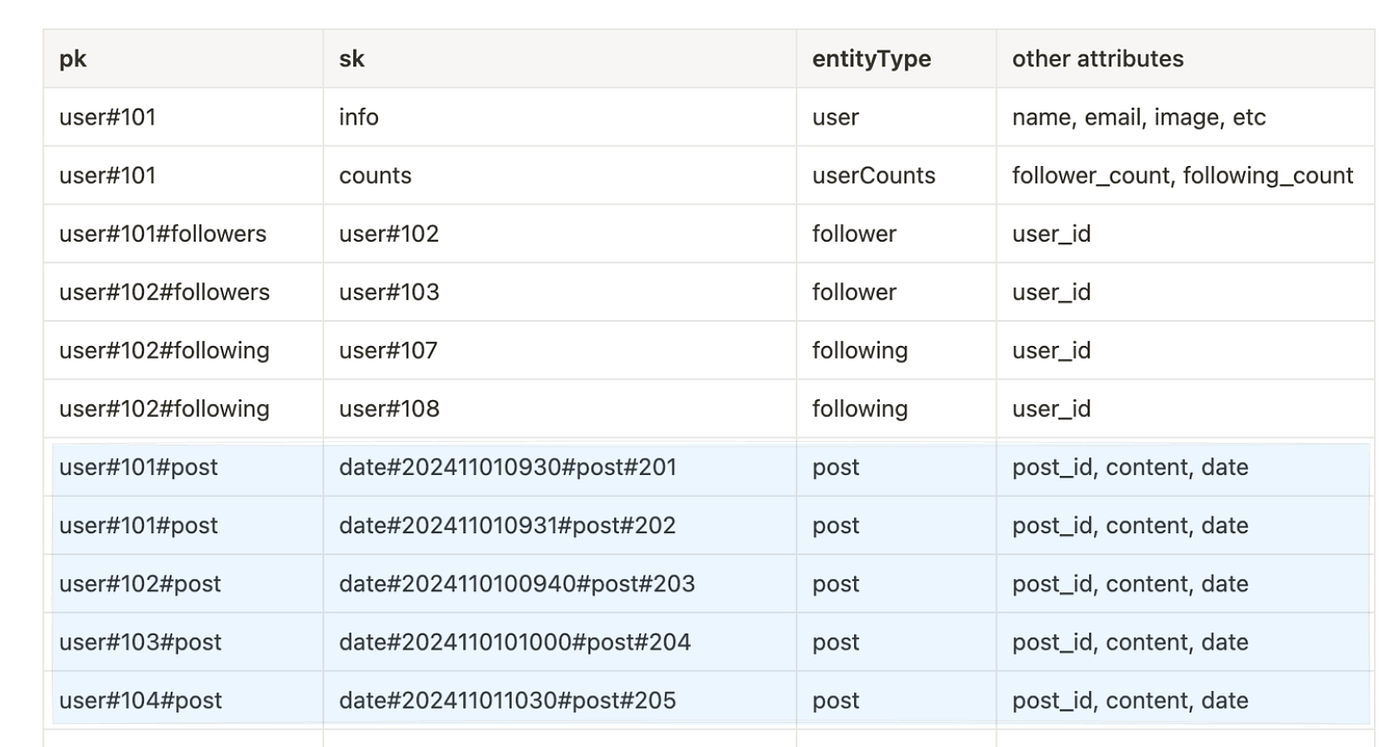
2. Get a user’s profile by their user ID
This is a simple query. We have the user’s ID we simply query for that in the partition key:
TableName: SocialMedia,
KeyConditionExpression: pk = "user#101" AND sk = "info"That would return the following user item.

3. Get posts created by a given user
This query is the same as the first query, but we only need a single query:
TableName: SocialMedia,
KeyConditionExpression: pk = "user#101#post" AND begins_with(sk, "date#")
ScanIndexForward: falseThis would return the following items.
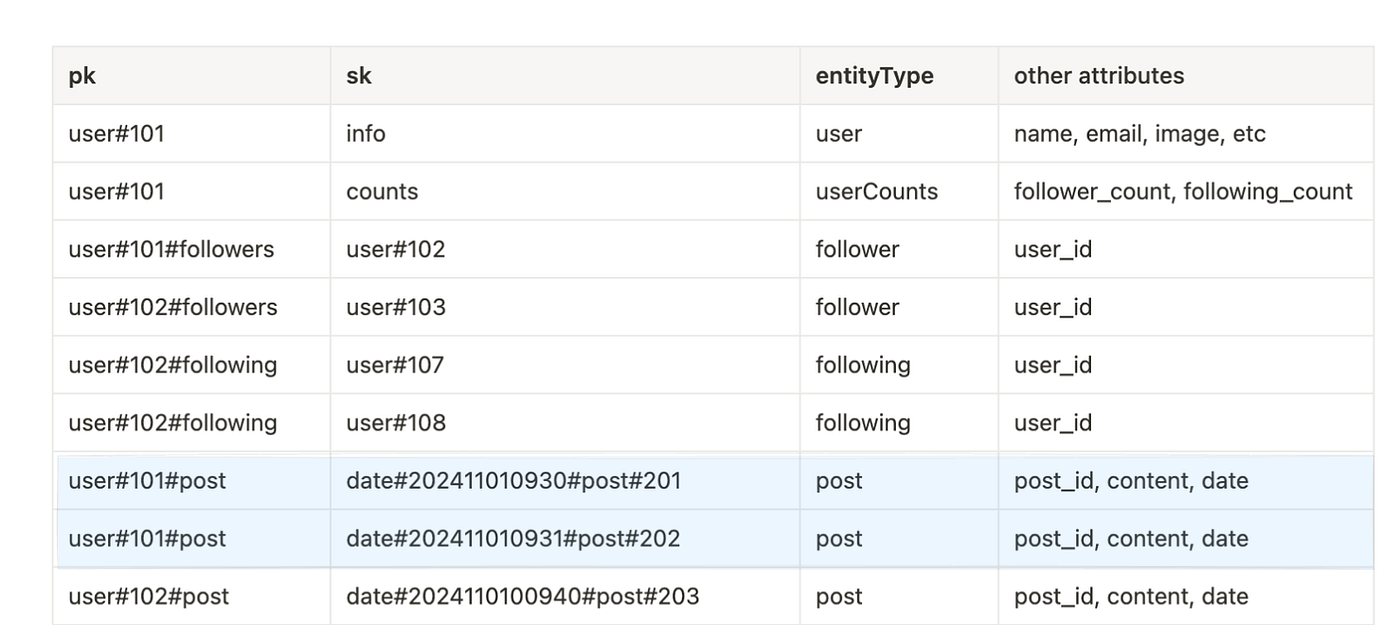
You can further fine-tune this query by asking for posts on a given date.
TableName: SocialMedia,
KeyConditionExpression: pk = "user#101#post" AND begins_with(sk, "date#20241101")This query will return only the posts created on a given day (November 1st, 2024).
4. Get a post by its post ID
To satisfy this access pattern we will need to create a GSI, using the postID for the partition key and “info” as the sort key.
TableName: SocialMedia,
IndexName: GSI1,
KeyConditionExpression: pk = "post#201" AND sk = "info"5. Get all comments on a given post
This access pattern is straightforward. We can query the partition key with “postID#comment” and get all comments.
TableName: SocialMedia,
KeyConditionExpression: pk = "post#201#comment" AND begins_with(sk, "date#")Here are the query results:
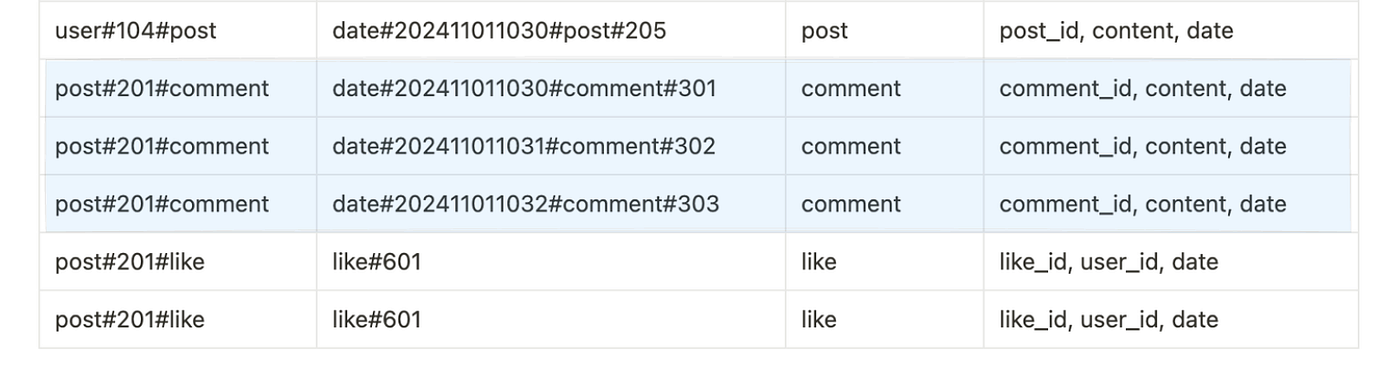
6. Get all likes on a given post
This query is pretty much the same as the previous one.
We have the “#like” suffix on every post like. The following query will fetch us all likes on a given post.
TableName: SocialMedia,
KeyConditionExpression: pk = "post#201#like" AND begins_with(sk, "like#")
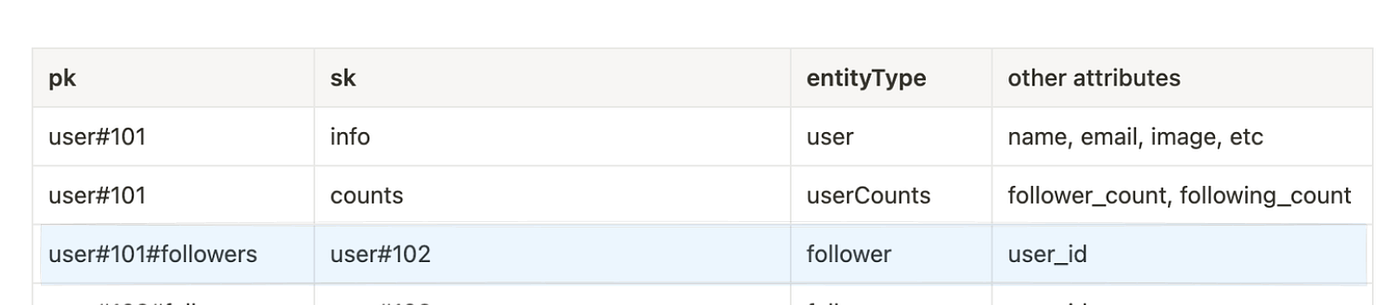
7. Get a user’s followers
A pretty common access pattern is to list all of the followers for a given user.
Recall earlier we write an item to the table everytime a user follows another user.
Here’s how we can satisfy this access pattern.
TableName: SocialMedia,
KeyConditionExpression: pk = "user#101#followers" AND begins_with(sk, "user#")And this yields the following result:
Summary
In this article, I guide you through designing a scalable database for a social media app using DynamoDB and a single-table design approach.
I start by identifying key access patterns, like fetching a user’s feed, retrieving individual posts, and listing comments, then show how to design partition and sort keys to make these queries efficient.
By using parallel queries and GSIs where necessary, I show you how this setup can handle massive read and write loads, giving a social media app the scalability needed to serve millions of users efficiently.
👋 My name is Uriel Bitton and I hope you learned something in this edition of Excelling With DynamoDB.
📅 If you're looking for help with DynamoDB, let's have a quick chat.
🙌 I hope to see you in next week's edition!